
Data is the lifeblood of machine learning, serving as the foundation upon which models learn and make predictions. Quality data fuels the training process, enabling algorithms to recognize patterns, make accurate decisions, and improve their performance. Without sufficient and relevant data, machine learning models lack the necessary information to understand, generalize, and derive meaningful insights.

Data preprocessing
Data cleaning and handling missing values
In the enchanting world of machine learning, data is the magical potion that fuels the power of algorithms. However, this data isn’t always perfect—it can be messy, incomplete, or even contain hidden flaws. To ensure the success of the magical learning process, two crucial spells are cast: Data Cleaning and Handling Missing Values.
Data Cleaning
Imagine a treasure trove guarded by a dragon—the treasure being valuable data and the dragon representing errors, outliers, or inconsistencies within it. Data cleaning is the heroic quest to conquer this dragon and purify the treasure trove for the machine’s consumption. There exist fundamental ideas:
- Removing Irrelevant Information: Sometimes, the treasure trove might contain irrelevant or redundant information. Cleaning involves identifying and removing these unnecessary bits, ensuring that only the most valuable data remains.
- Dealing with Outliers: These are anomalies, like a rogue knight in a gathering of peasants. Data cleaning involves either correcting these anomalies if they’re genuine or removing them if they disrupt the learning process.
- Handling Inconsistencies: Imagine a map with conflicting paths—data inconsistencies can lead to confusion. Cleaning involves ensuring consistency across the dataset, fixing discrepancies to maintain accuracy.
Example for data cleaning in Python
Here is a simple example of how to remove outliers in a dataset using a simple threshold in Python.
import pandas as pd
import numpy as np
# Creating a sample dataset with student grades and ages
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emily'],
'Age': [18, 20, 17, 45, 16], # Including an outlier (45 years old)
'Grade': [85, 78, 90, 60, 92]
}
df = pd.DataFrame(data)
# Displaying the original dataset
print("Original Dataset:")
print(df)
# Removing outliers based on age using a simple threshold
age_mean = df['Age'].mean()
age_std = df['Age'].std()
lower_bound = age_mean - 2 * age_std
upper_bound = age_mean + 2 * age_std
# Removing outliers
df_filtered = df[(df['Age'] >= lower_bound) & (df['Age'] <= upper_bound)]
# Displaying the filtered dataset without outliers
print("\nFiltered Dataset (without outliers):")
print(df_filtered)In this example, a DataFrame representing student data with ‘Name’, ‘Age’, and ‘Grade’ columns is created. Then the mean and standard deviation of the ‘Age’ column is calculated to identify outliers using a threshold of ±2 standard deviations from the mean. Finally, the dataset is filtered to remove rows where the ‘Age’ column falls outside this threshold, resulting in a dataset without outliers.
Handling Missing Values
In this magical land, sometimes parts of the treasure map might be missing, making the journey challenging. These missing pieces in the data can hinder the machine’s learning process. Handling missing values is the art of filling these gaps or deciding what to do in their absence.
1. Identifying Missing Values: Wizards, equipped with their knowledge, spot these missing pieces—be it empty fields or placeholders like “NA” or “null.”
2. Strategies for Handling: The wise wizards have various spells to tackle missing values. They might choose to:
- Impute Data: Fill in missing values using techniques like mean, median, or mode.
- Drop Rows or Columns: If the missing values are too many or critical, wizards may choose to remove corresponding rows or columns.
- Predictive Imputation: Advanced wizards might use other features to predict and fill missing values.
By mastering the art of Data Cleaning and Handling Missing Values, the enchanting world of machine learning ensures that the magical learning process remains robust, allowing algorithms to learn from the purest and most complete treasure trove of data.
Feature scaling and normalization
In the realm of machine learning, where algorithms wield their magic upon datasets, Feature Scaling and Normalization are potent enchantments that ensure fairness and harmony among the attributes of these datasets.
Feature Scaling
Imagine a magical forest where various creatures—some tall, some small—reside. Just as these creatures differ in size, the attributes (or features) in a dataset can also vary widely. Feature Scaling is the act of bringing these attributes to a similar scale, ensuring that no single feature overpowers the others due to its magnitude.
- Uniform Scaling: Just as a wizard might resize creatures to a standard height in the magical forest, feature scaling transforms attributes to a uniform scale. This could involve techniques like Min-Max Scaling or Rescaling, where the values are adjusted to fit within a specific range, often between 0 and 1.
- Standardization: Another technique involves transforming attributes to have a mean of zero and a standard deviation of one. This ensures that the attributes follow a standard normal distribution, making them more comparable.
By employing Feature Scaling, the magical algorithms can learn from the dataset more efficiently, as no single attribute holds undue influence due to its scale.
Normalization
In the enchanted kingdom of machine learning, attributes might not just vary in scale but also in nature. Some might be measured in different units, while others might span vastly different ranges. Normalization steps in to create a level playing field for these attributes.
- Unit Scaling: Imagine converting all measures into the same unit, say, magical points. Normalization brings diverse attributes onto a common scale, making them directly comparable. One common method is to normalize features to have a unit norm, ensuring they lie on a unit hypersphere.
- Z-score Normalization: Similar to standardization in feature scaling, this technique transforms attributes to have a mean of zero and a standard deviation of one. However, normalization techniques might work better when dealing with attributes that don’t necessarily follow a normal distribution.
By weaving the enchantment of Feature Scaling and Normalization, the magical algorithms of machine learning can gracefully navigate through datasets, treating each attribute with equal importance, and ensuring fair and effective learning.
Example for feature scaling and normalization in Python
This is an example showcasing uniform scaling (min-max scaling) and standardization (Z-score normalization) using Python and the sklearn library.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import numpy as np
# Creating sample data
data = np.array([[10, 20, 30],
[15, 25, 35],
[20, 30, 40]])
print("Original Data:")
print(data)
# Min-max scaling (uniform scaling)
scaler_minmax = MinMaxScaler()
data_minmax = scaler_minmax.fit_transform(data)
print("\nMin-Max Scaled Data:")
print(data_minmax)
# Standardization (Z-score normalization)
scaler_standard = StandardScaler()
data_standard = scaler_standard.fit_transform(data)
print("\nStandardized Data:")
print(data_standard)Will output:
Original Data:
[[10 20 30]
[15 25 35]
[20 30 40]]
Min-Max Scaled Data:
[[0. 0. 0. ]
[0.5 0.5 0.5]
[1. 1. 1. ]]
Standardized Data:
[[-1.22474487 -1.22474487 -1.22474487]
[ 0. 0. 0. ]
[ 1.22474487 1.22474487 1.22474487]]This example uses the MinMaxScaler for uniform scaling (min-max scaling) and the StandardScaler for standardization (Z-score normalization) on a sample dataset data.
- Min-max scaling transforms the data to a specified range (commonly [0, 1]), preserving the relationships between data points.
- Standardization normalizes the data to have a mean of 0 and standard deviation of 1, making the data centered around zero and expressed in terms of standard deviations.
Data transformation and encoding
In the mystical world of machine learning, Data Transformation and Encoding are powerful spells that shape and mold raw data into a form that the magical algorithms can comprehend and learn from effectively.
Data Transformation
Imagine a diverse landscape with elements of different shapes and sizes—just like the varied attributes in a dataset. Data Transformation is the magical art of reshaping and altering these attributes to make them more suitable for the learning process.
- Feature Engineering: Wizards skilled in feature engineering craft new attributes from existing ones, unveiling hidden patterns or creating more informative features. For example, they might create a new feature by combining or extracting information from existing attributes.
- Dimensionality Reduction: Just as a wizard might merge smaller elements into a single entity, dimensionality reduction techniques like Principal Component Analysis (PCA) or t-SNE transform and compress attributes into a lower-dimensional space, retaining essential information while reducing complexity.
PCA helps in reducing the number of features while retaining the important information. This is an example of how a wizard can do dimensionality reduction using PCA in Python using the scikit-learn library.
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Load the iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Apply PCA
pca = PCA(n_components=2) # Reduce to 2 dimensions
X_pca = pca.fit_transform(X)
# Visualize the reduced data
plt.figure(figsize=(8, 6))
for i, target_name in enumerate(iris.target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], label=target_name)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS dataset')
plt.legend()
plt.show()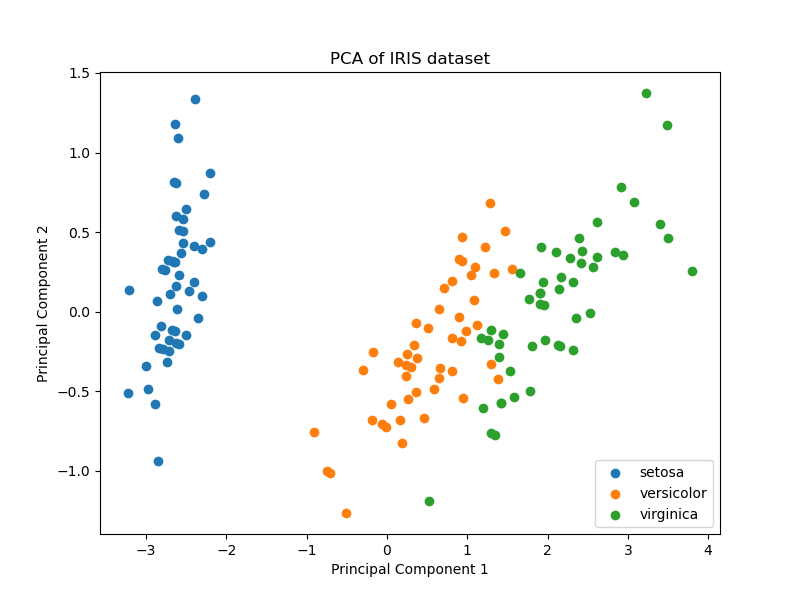
Encoding
In the enchanted realm, data often speaks in diverse tongues—categorical, numerical, or textual. Encoding is the enchantment that translates these various languages into a common tongue that the algorithms can understand.
- One-Hot Encoding: Categorical variables like colors or categories of magical creatures are transformed into binary vectors, representing each category as a unique combination of 0s and 1s. This ensures that categorical data can be processed numerically.
- Label Encoding: Sometimes, categorical data follows a natural order, like small, medium, and large. Label Encoding assigns a numerical value to these categories, preserving the order in the transformation.
- Text Encoding (Word Embedding): For textual data, wizards employ techniques like Word Embedding (e.g., Word2Vec, GloVe) to convert words or sentences into numerical vectors, capturing semantic relationships and meanings.
This is an example of how you a wizard works with word embeddings using Python and the gensim library, which provides tools for topic modeling, document indexing, and word vector representations.
from gensim.models import Word2Vec
# Sample sentences for training word embeddings
sentences = [
['machine', 'learning', 'is', 'exciting'],
['natural', 'language', 'processing', 'is', 'fun'],
['deep', 'learning', 'is', 'challenging'],
['I', 'enjoy', 'learning', 'new', 'things']
]
# Train Word2Vec model
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Test the trained model
print("Similarity between 'machine' and 'learning':", model.wv.similarity('machine', 'learning'))
print("Similarity between 'natural' and 'processing':", model.wv.similarity('natural', 'processing'))
print("Word vector for 'deep':", model.wv['deep'])Will output:
Similarity between 'machine' and 'learning': 0.13725272
Similarity between 'natural' and 'processing': -0.07424272
Word vector for 'deep': [ 8.1681060e-03 -4.4430252e-03 8.9854356e-03 8.2536628e-03
-4.4352217e-03 3.0310318e-04 4.2744810e-03 -3.9263200e-03
-5.5599599e-03 -6.5123201e-03 -6.7074812e-04 -2.9592411e-04
4.4630864e-03 -2.4740696e-03 -1.7260083e-04 2.4618772e-03
4.8675835e-03 -3.0819760e-05 -6.3394117e-03 -9.2607923e-03
2.6655656e-05 6.6618980e-03 1.4660070e-03 -8.9665242e-03
-7.9386076e-03 6.5518981e-03 -3.7856775e-03 6.2550008e-03
-6.6810325e-03 8.4796660e-03 -6.5163355e-03 3.2880050e-03
-1.0569846e-03 -6.7875329e-03 -3.2875864e-03 -1.1614148e-03
-5.4709283e-03 -1.2113330e-03 -7.5633037e-03 2.6466744e-03
9.0701366e-03 -2.3772405e-03 -9.7652391e-04 3.5135737e-03
8.6650820e-03 -5.9218691e-03 -6.8875649e-03 -2.9329681e-03
9.1477036e-03 8.6627214e-04 -8.6784009e-03 -1.4469642e-03
9.4794808e-03 -7.5494922e-03 -5.3580846e-03 9.3165776e-03
-8.9737223e-03 3.8259220e-03 6.6545239e-04 6.6607152e-03
8.3127543e-03 -2.8507775e-03 -3.9923242e-03 8.8979146e-03
2.0896515e-03 6.2489314e-03 -9.4457045e-03 9.5901312e-03
-1.3482962e-03 -6.0521076e-03 2.9925376e-03 -4.5662181e-04
4.7064973e-03 -2.2830293e-03 -4.1378541e-03 2.2779114e-03
8.3543761e-03 -4.9956162e-03 2.6686836e-03 -7.9905661e-03
-6.7733568e-03 -4.6765798e-04 -8.7677166e-03 2.7894336e-03
1.5985981e-03 -2.3196822e-03 5.0037750e-03 9.7487951e-03
8.4542790e-03 -1.8802247e-03 2.0581563e-03 -4.0036901e-03
-8.2414001e-03 6.2779565e-03 -1.9491804e-03 -6.6620606e-04
-1.7713457e-03 -4.5356560e-03 4.0617124e-03 -4.2701899e-03]By weaving the enchantments of Data Transformation and Encoding, the raw and diverse data in the magical realm is refined and unified, ready to be embraced by the learning algorithms. This transformation and encoding pave the way for clearer insights and more effective learning experiences for these mystical algorithms.